

和機遇有哪些?")
 400-993-9050
400-993-9050 
人工文本分類的挑戰(zhàn)和機遇有哪些?

人工(AI)文本分類是自然語言處理(NLP)中的一個重要領域,其目標是將文本數(shù)據(jù)根據(jù)其內容和特征進行分類。隨著大數(shù)據(jù)和計算能力的快速發(fā)展,文本分類技術在各個領域得到了廣泛應用,包括情感分析、垃圾郵件過濾、主題分類等。然而,盡管這一領域取得了顯著的進展,仍然面臨著諸多挑戰(zhàn),同時也蘊含著巨大的機遇。
挑戰(zhàn)一:數(shù)據(jù)質量與數(shù)據(jù)不平衡
數(shù)據(jù)質量是文本分類中的一個關鍵問題。文本數(shù)據(jù)通常來源于不同的渠道,其質量參差不齊。如果輸入的數(shù)據(jù)包含大量噪聲或標注錯誤,那么分類模型的訓練效果將受到嚴重影響。為了提高模型的準確性,必須對數(shù)據(jù)進行清洗和預處理,這是一項既耗時又復雜的任務。

此外,數(shù)據(jù)不平衡也是一個普遍存在的問題。在許多實際應用中,某些類別的樣本可能遠遠多于其他類別。這種類別不平衡會導致模型偏向于樣本較多的類別,從而降低對樣本較少類別的性能。解決數(shù)據(jù)不平衡問題的方法包括重采樣技術(如過采樣和欠采樣)、生成對抗網(wǎng)絡(GANs)和數(shù)據(jù)增強等。
挑戰(zhàn)二:語言的多樣性與復雜性
自然語言具有極大的多樣性和復雜性。不同的語言、方言、語境和風格都會影響文本的表達方式。此外,同一詞匯在不同語境下可能具有不同的意義,這就增加了文本分類的難度。對于多語言文本分類,模型需要能夠處理不同語言的特性和結構,這對模型的設計和訓練提出了更高的要求。
為了應對語言的復雜性,研究者們通常使用詞嵌入技術(如Word2Vec、GloVe)和上下文表示技術(如BERT、GPT)來捕捉文本中的語義信息。然而,即使是很先進的技術,也無法語言中的所有歧義問題,因此持續(xù)改進模型的能力仍然是一個挑戰(zhàn)。
挑戰(zhàn)三:上下文理解與語義推理
的文本分類不僅需要對詞匯進行分類,還需要理解文本的上下文和語義。例如,在情感分析中,單一的詞匯可能無法準確反映整體情感,只有結合上下文才能得到正確的判斷。此外,文本中的隱含信息和推理能力也是模型必須具備的特性。傳統(tǒng)的分類模型往往難以處理復雜的上下文和語義推理任務。
為了解決這一問題,近年來出現(xiàn)了許多基于深度學習的模型,如長短期記憶網(wǎng)絡(LSTM)和變換器模型(Transformer),它們能夠地捕捉文本中的長距離依賴關系和上下文信息。然而,這些模型的計算復雜度和資源消耗也是需要考慮的重要因素。
機遇一:技術進步帶來的新方法
隨著深度學習技術的快速發(fā)展,文本分類領域也迎來了許多創(chuàng)新的方法。例如,基于變換器的模型(如BERT、GPT)在許多文本分類任務中取得了顯著的突破。這些模型通過預訓練和微調的策略,能夠在大規(guī)模數(shù)據(jù)上學習到豐富的語言表示,從而提升了分類任務的準確性和魯棒性。
此外,遷移學習和預訓練模型的應用也為文本分類提供了新的機遇。通過遷移學習,模型可以在一個任務上學習到的知識遷移到另一個相關任務上,從而減少對大量標注數(shù)據(jù)的依賴。這不僅提高了分類的效率,還降低了成本。
機遇二:跨領域應用與化服務
文本分類技術的應用范圍非常廣泛。在商業(yè)領域,文本分類可以用于客戶反饋分析、市場調研、產(chǎn)品等;在領域,它可以用于電子健康記錄的自動分類和疾病;在社交媒體中,它可以用于輿情監(jiān)測和內容過濾。隨著化服務的發(fā)展,文本分類技術將成為提升服務質量和用戶體驗的重要工具。
例如,在電子商務平臺中,自動分類技術可以幫助對用戶評論進行情感分析,從而為商家提供有價值的用戶反饋。在領域,文本分類可以幫助醫(yī)生從大量的醫(yī)學文獻中篩選出與患者病情相關的信息,提高診斷的準確性和效率。
機遇三:數(shù)據(jù)共享與開放資源
數(shù)據(jù)共享和開放資源為文本分類技術的發(fā)展提供了豐富的資源。許多組織和研究機構已經(jīng)發(fā)布了高質量的標注數(shù)據(jù)集,如IMDB情感分析數(shù)據(jù)集、20 Newsgroups數(shù)據(jù)集等,這些數(shù)據(jù)集為模型的訓練和評估提供了寶貴的資源。此外,開源的機器學習框架和工具(如TensorFlow、PyTorch)也使得文本分類技術的研究和應用變得更加便捷。
通過共享數(shù)據(jù)和開源工具,研究人員和開發(fā)者可以更快地進行實驗和創(chuàng)新,從而推動文本分類技術的進步。同時,這也促進了跨學科的合作和知識的傳播,進一步拓展了文本分類技術的應用前景。
結論
人工文本分類技術在面臨挑戰(zhàn)的同時,也充滿了機遇。數(shù)據(jù)質量與數(shù)據(jù)不平衡、語言的多樣性與復雜性、上下文理解與語義推理等挑戰(zhàn)需要通過不斷的技術創(chuàng)新和優(yōu)化來解決。而技術進步、新方法的出現(xiàn)、跨領域的應用以及數(shù)據(jù)共享和開放資源則為文本分類技術的發(fā)展提供了廣闊的前景。
在未來,隨著技術的不斷演進和應用場景的不斷擴展,文本分類將會在更多領域發(fā)揮重要作用。我們期待在解決挑戰(zhàn)的過程中,能夠不斷開拓新的機遇,為各個帶來更多的價值。
關于我們
360億方云是一款專為企業(yè)打造的團隊協(xié)作與知識管理平臺,它可以輕松實現(xiàn)海量文件的存儲和管理,支持在線編輯、多格式預覽、全文檢索、文件評論和安全管控等功能。360億方云為企業(yè)提供了一個知識庫,幫助企業(yè)成員共同管理和協(xié)作文件資產(chǎn),提高內外部協(xié)同效率,保障數(shù)據(jù)安全和風險控制。
360億方云已經(jīng)服務了很多企業(yè),其中包括浙江大學、碧桂園、長安汽車、吉利集團、晶科能源、金圓集團等大型客戶。
-
本文分類: 常見問題
-
本文標簽:
-
瀏覽次數(shù): 2598 次瀏覽
-
發(fā)布日期: 2024-07-25 10:00:08



熱門推薦
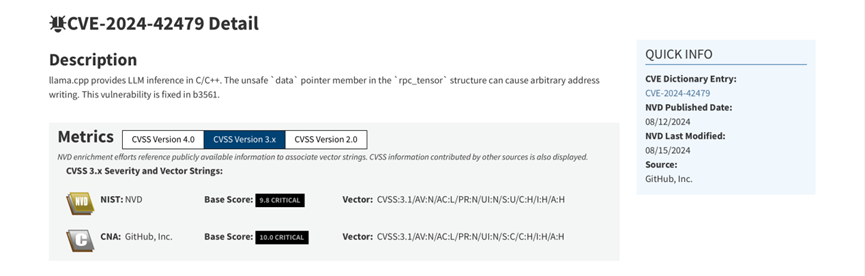
- 360告警:全球知名大模型框架被曝漏洞!或致AI設備集體失控
- 360億方云助力500強企業(yè)晶科能源實現(xiàn)多地高效協(xié)同
- 入選領域最多、影響力最廣泛!360上榜《2024網(wǎng)絡安全十大創(chuàng)新方向》
- 華諾科技與360億方云達成戰(zhàn)略合作,共推AI大模型產(chǎn)業(yè)化落地
- 360億方云AI增值服務上線,超大限時優(yōu)惠等你來!
- 央企控股上市公司引入360億方云企業(yè)網(wǎng)盤,搭建智慧協(xié)同云平臺
- 江蘇霍普律師事務所攜手360億方云,提升案件協(xié)作效率
- 中國水利水電第七工程局、北京石油化工學院等簽約360億方云
- 中國酒業(yè)巨頭引入360億方云企業(yè)網(wǎng)盤,安全管理文件、團隊高效協(xié)同
- 數(shù)字政府新標桿!朝陽“City不City啊”?

最新推薦
- 讓知識成為企業(yè)AI生產(chǎn)力!360AI企業(yè)知識庫SaaS版開放公測
- 航空AI白皮書發(fā)布,重塑航空未來,讓知識成為生產(chǎn)力
- 入選領域最多、影響力最廣泛!360上榜《2024網(wǎng)絡安全十大創(chuàng)新方向》
- 數(shù)字政府新標桿!朝陽“City不City啊”?
- 360攜20+“終端能力者”!組建ISC終端安全生態(tài)聯(lián)盟
- 360告警:全球知名大模型框架被曝漏洞!或致AI設備集體失控
- 家人們,咱安全圈可不興“沒苦硬吃”!
- 《黑神話:悟空》瘋狂24小時:爆火下的網(wǎng)絡安全陷阱
- 攻防演練實錄 | 360安全大模型再狙0day漏洞,助藍隊“上大分”!
- Gartner最新報告!360“明星產(chǎn)品”搭載安全大模型戰(zhàn)力領跑市場






 浙公網(wǎng)安備 33011002015048號
浙公網(wǎng)安備 33011002015048號 預約顧問
預約顧問
 電話咨詢
電話咨詢